Unleashing the power of reinforcement learning
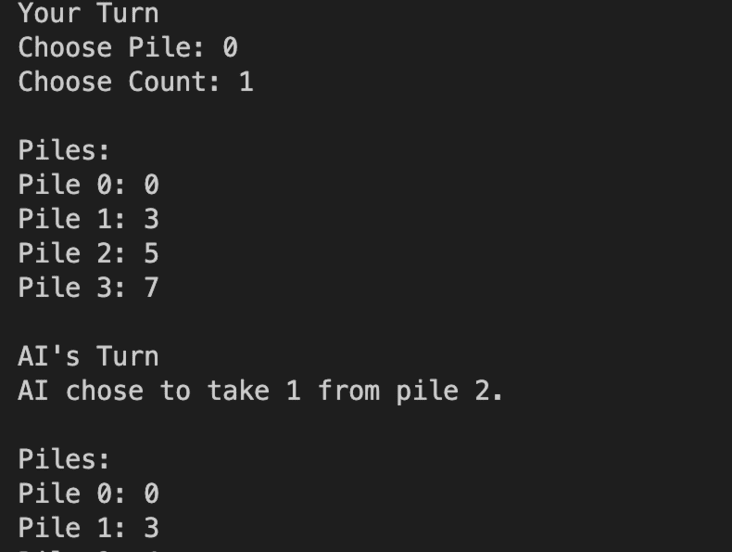
Nim is a historical game in which there are “n” piles of “m” objects. The actual numbers can be chosen by the players of the game. Two players take turns removing as many objects as they want from any one pile at a time. The objective of the game is to avoid being the last person to take the last object from the board, as doing so results in a loss.
This project is one of the many AI-related projects that I have completed in my quest to de-mystify artificial intelligence. While many courses can teach the theory behind these complex algorithms and infrastructures, I wanted to actually implement some of them. As the legendary Richard Feynman stated, “What I cannot create, I do not understand.”
This project’s objective was simple: use reinforcement learning to teach an ML model to see a reward in moves that result in winning a game, a punishment in moves that result in losing a game, and neutral feedback when moves resulted in the game progressing.
The specific type of machine learning that this project uses is known as Q-learning, in which “Q-values” of (state, action) pairs are updated according to this formula:

where alpha represents the “learning rate,” or how much more valuable new information is compared to old information.
These Q values are stored in a Python dictionary mapping (state, action) pairs to their respective Q values.
Taking all of the current Q-values and (state, action) pairs, I then implemented a function that chooses the best move to take. This function normally is implemented using a greedy algorithm that chooses the best Q value. However, the function can also take an optional parameter “epsilon,” which would result in an epsilon-greedy algorithm (in which a random move is taken with epsilon probability).
The model is then trained by playing against itself up to 100,000 times, collecting the data that fine-tunes its Q-learning strategy.
This project truly opened up my imagination in the realm of machine learning, and I sat at my desk in awe as I watched the AI play against itself, thousands of times in seconds…
*p.s. it should go without saying: I didn’t win a single game.